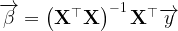Project Euler is a site that has math problems that can be solved with the assistance of a computer program (solving the problems without programming would take an unreasonable amount of time). The problems are fun and they are a good way to learn a programming language and some interesting math.
A few years ago I solved the first 77 problems using Common Lisp.
I intend to eventually continue solving more, maybe switching from Lisp to Matlab, Mathematica, or some other language.
The site requests that users do not share solutions, which I have no intention of doing. However, I did accumulate some helper functions that I wrote while solving the problems, and I think they could be helpful for people getting started on Project Euler using Common Lisp.
I just came across the following video from WeUseMath.org. The site aims to answer the question “When will I use math?”
Today’s quote of the day is from David Bailey (at 4:52 in the video).
It’s worth doing. It’s something that, I’ve never heard anyone say, “I wish I didn’t take so much math.”
I cannot recall anyone I know expressing regret for taking too many math courses, but I have heard people express regret for taking too few.
I’m reminded of the following quote from Paul Graham.
But while you don’t literally need math for most kinds of hacking, in the sense of knowing 1001 tricks for differentiating formulas, math is very much worth studying for its own sake. It’s a valuable source of metaphors for almost any kind of work. I wish I’d studied more math in college for that reason.
The video also reminded me of the following quote from Steven Landsburg.
If you enjoy mathematics, and have a knack for it, you cannot go wrong by taking math courses no matter where you think you’re eventually headed. Top-ranked economics Ph.D. programs almost always prefer to admit students with strong math backgrounds over students with strong economics backgrounds; I’m told the same is true in biology and I suspect it’s the same way in many other disciplines. In the economics department where I teach, we frequently admit math majors with few (or even zero!) economics courses on their transcripts; we would never admit an economics major with inadequate math training.
Fortunately, with all the free courses available on the internet, it’s now possible to take more math (for free!). Check out the OCW Consortium site for information on available courses. For another example of mathematicians faring well, check out the Wall Street Journal’s 2009 article, Doing the Math to Find the Good Jobs.
Wikipedia has the following definition for combination:
In mathematics a combination is a way of selecting several things out of a larger group, where (unlike permutations) order does not matter. In smaller cases it is possible to count the number of combinations. For example given three fruit, an apple, orange and pear say, there are three combinations of two that can be drawn from this set: an apple and a pear; an apple and an orange; or a pear and an orange. More formally a k–combination of a set S is a subset of k distinct elements of S. If the set has n elements the number of k-combinations is equal to the binomial coefficient
The binomial coefficient indexed by n and k is denoted . The formula below, for evaluating binomial coefficients, uses factorials.
This series of posts covers the installation of WeBWork. This post, Part IV of the series, will cover how to configure your WeBWork server so that you can access the 20,000 freely available problems.
… Continued from Part III
The last post of this series, Part III, concluded with an image showing the virtual machine and the WeBWork site loaded on my computer. Let’s pick up where we left off, by loading the virtual machine and pointing our browser to http://localhost:14627/webwork2. It is not necessary to log in to the wwadmin account on the Ubuntu machine, as Apache will serve the web pages without logging in. However, it is necessary that the virtual machine is turned on. The window can be minimized to free desktop space. I should mention at this point that I logged into the wwadmin account a few days ago and updated the machine’s software using Ubuntu’s update manager. I am not exactly sure why, but this caused problems with the WeBWork installation (i.e., I received errors when trying to use the site), so I reverted to an earlier snapshot of the virtual machine. I wanted to mention this in case you were considering upgrading the software. An upgrade of the WeBWork software would possibly solve the issues that I was having, but I have not tried this yet.
I am going to try to start posting more frequently. This post covers topics that I’ve been thinking about lately, including model estimation with ordinary least squares (OLS) and forecasting when OLS is used to fit a statistical model with a dependent variable that is a transformation of some variable we wish to forecast.
Suppose we run a regression with the following specification:
Let’s assume that the error term is distributed normally, and let’s use OLS to solve for the coefficients in the model. Using a superscript to denote the m observations in the dataset, our m-by-n+1 design matrix is
If the coefficient vector is labeled and the vector containing the Y variable’s values is labeled , then the OLS estimation for the coefficients can be calculated by solving for .
Now we have a set of coefficients that we can use to predict values of Y when we receive additional observations that have values for our independent variables X1, X2, …, Xn, and no observed values of Y. Everything is fine.

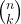 . The formula below, for evaluating binomial coefficients, uses factorials.
. The formula below, for evaluating binomial coefficients, uses factorials.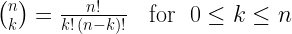

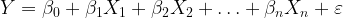
 is
is![\left[\begin{array}{ccccc} 1 & X_{1}^{(1)} & X_{2}^{(1)} & \cdots & X_{n}^{(1)}\\ 1 & X_{1}^{(2)} & X_{2}^{(2)} & \cdots & X_{n}^{(2)}\\ \vdots & \vdots & \vdots & \ddots & \vdots\\ 1 & X_{1}^{(m)} & X_{2}^{(m)} & \cdots & X_{n}^{(m)}\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+X_%7B1%7D%5E%7B%281%29%7D+%26+X_%7B2%7D%5E%7B%281%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%281%29%7D%5C%5C+1+%26+X_%7B1%7D%5E%7B%282%29%7D+%26+X_%7B2%7D%5E%7B%282%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%282%29%7D%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots%5C%5C+1+%26+X_%7B1%7D%5E%7B%28m%29%7D+%26+X_%7B2%7D%5E%7B%28m%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%28m%29%7D%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000&s=1&c=20201002)
 and the vector containing the Y variable’s values is labeled
and the vector containing the Y variable’s values is labeled  , then the OLS estimation for the coefficients can be calculated by solving
, then the OLS estimation for the coefficients can be calculated by solving 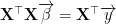 for
for