I am going to try to start posting more frequently. This post covers topics that I’ve been thinking about lately, including model estimation with ordinary least squares (OLS) and forecasting when OLS is used to fit a statistical model with a dependent variable that is a transformation of some variable we wish to forecast.
Suppose we run a regression with the following specification:
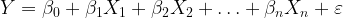
Let’s assume that the error term is distributed normally, and let’s use OLS to solve for the coefficients in the model. Using a superscript to denote the m observations in the dataset, our m-by-n+1 design matrix 
![\left[\begin{array}{ccccc} 1 & X_{1}^{(1)} & X_{2}^{(1)} & \cdots & X_{n}^{(1)}\\ 1 & X_{1}^{(2)} & X_{2}^{(2)} & \cdots & X_{n}^{(2)}\\ \vdots & \vdots & \vdots & \ddots & \vdots\\ 1 & X_{1}^{(m)} & X_{2}^{(m)} & \cdots & X_{n}^{(m)}\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+X_%7B1%7D%5E%7B%281%29%7D+%26+X_%7B2%7D%5E%7B%281%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%281%29%7D%5C%5C+1+%26+X_%7B1%7D%5E%7B%282%29%7D+%26+X_%7B2%7D%5E%7B%282%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%282%29%7D%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots%5C%5C+1+%26+X_%7B1%7D%5E%7B%28m%29%7D+%26+X_%7B2%7D%5E%7B%28m%29%7D+%26+%5Ccdots+%26+X_%7Bn%7D%5E%7B%28m%29%7D%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000&s=1&c=20201002)
If the coefficient vector is labeled 

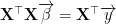
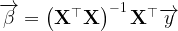
Now we have a set of coefficients that we can use to predict values of Y when we receive additional observations that have values for our independent variables X1, X2, …, Xn, and no observed values of Y. Everything is fine.
Now suppose that our original specification was not a good fit for the data and the error terms were not distributed normally. After messing around with the specification, we find that taking the natural logarithm of Y produces a much better fit, and has normally distributed errors. Our new specification is

If we repeat the steps described above, we can estimate a new set of coefficients by calculating 

We now have a set of coefficients that we can use to predict values of log(Y) when we receive additional observations that have values for our independent variables X1, X2, …, Xn, and no observed value of Y. However, we want to predict Y. It may seem natural to just predict Y by taking the exponential function of the predicted value of log(Y). This is where a problem occurs. Our regression is basically returning coefficient values that can be used to express the expected value of the dependent variable, conditioned on the observed values of the independent variables. More formally,
![\mathbb{E}\left[\log\left(Y\right)|X_{1},X_{2},\ldots,X_{n}\right]=\beta_{0}+\beta_{1}X_{1}+\beta_{2}X_{2}+\ldots+\beta_{n}X_{n}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Clog%5Cleft%28Y%5Cright%29%7CX_%7B1%7D%2CX_%7B2%7D%2C%5Cldots%2CX_%7Bn%7D%5Cright%5D%3D%5Cbeta_%7B0%7D%2B%5Cbeta_%7B1%7DX_%7B1%7D%2B%5Cbeta_%7B2%7DX_%7B2%7D%2B%5Cldots%2B%5Cbeta_%7Bn%7DX_%7Bn%7D&bg=ffffff&fg=000&s=1&c=20201002)
While it may seem natural to just take the exponential function of the predicted value of log(Y) to predict Y, Jensen’s Inequality implies that ![\mathbb{E}\left[f\left(X\right)\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bf%5Cleft%28X%5Cright%29%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![f\left(\mathbb{E}\left[X\right]\right)](https://s0.wp.com/latex.php?latex=f%5Cleft%28%5Cmathbb%7BE%7D%5Cleft%5BX%5Cright%5D%5Cright%29&bg=ffffff&fg=000&s=0&c=20201002)


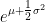

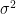
![\mathbb{E}\left[Y|X_{1},X_{2},\ldots,X_{n}\right]=\exp\left(\mathbb{E}\left[\log\left(Y\right)|X_{1},X_{2},\ldots,X_{n}\right]+\frac{1}{2}MSE\right)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BY%7CX_%7B1%7D%2CX_%7B2%7D%2C%5Cldots%2CX_%7Bn%7D%5Cright%5D%3D%5Cexp%5Cleft%28%5Cmathbb%7BE%7D%5Cleft%5B%5Clog%5Cleft%28Y%5Cright%29%7CX_%7B1%7D%2CX_%7B2%7D%2C%5Cldots%2CX_%7Bn%7D%5Cright%5D%2B%5Cfrac%7B1%7D%7B2%7DMSE%5Cright%29&bg=ffffff&fg=000&s=1&c=20201002)
The MSE can be calculated by taking the model’s sum of squared errors, and dividing by the number of observations minus the number of independent variables in the model minus 1.
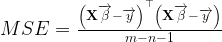
Using ![\mathbb{E}\left[\log\left(Y\right)|X_{1},X_{2},\ldots,X_{n}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Clog%5Cleft%28Y%5Cright%29%7CX_%7B1%7D%2CX_%7B2%7D%2C%5Cldots%2CX_%7Bn%7D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}\left[Y|X_{1},X_{2},\ldots,X_{n}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BY%7CX_%7B1%7D%2CX_%7B2%7D%2C%5Cldots%2CX_%7Bn%7D%5Cright%5D&bg=ffffff&fg=000&s=1&c=20201002)
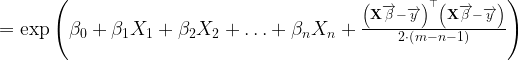
The formula above can be used to predict values of Y using the coefficients estimated by OLS for our log-linear model, and observed values of the independent variables. However, the adjustment is not always so simple. In some cases, more work would be required to calculate how to predict Y when other functions besides the natural logarithm are used to transform Y. In such cases, it might be a good idea to use a different method to model the data, as opposed to trying to transform the variables such that coefficients can be estimated using OLS. While the OLS results often have an intuitive appeal, which can be useful for inference, other models might be more suited for forecasting.