Matrix factorization algorithms factorize a matrix D into two matrices P and Q, such that D ≈ PQ. By limiting the dimensionality of P and Q, PQ provides a low-rank approximation of D. While singular value decomposition (SVD) can also be used for this same task, the matrix factorization algorithms considered in this post accommodate missing data in matrix D, unlike SVD.
For an overview of matrix factorization, I recommend Albert Au Yeung’s tutorial. That post describes matrix factorization, motivates the problem with a ratings prediction task, derives the gradients used by stochastic gradient descent, and implements the algorithm in Python.
For exploratory work, it would be great if the algorithm could be implemented in such a way that the gradients could be automatically derived. With such an approach, gradients would not have to be re-derived when e.g., a change is made to the loss function (either the error term and/or the regularization term). In general, automatically derived gradients for machine learning problems facilitate increased exploration of ideas by removing a time-consuming step.
Theano is a Python library that allows users to specify their problem symbolically using NumPy-based syntax. The expressions are compiled to run efficiently on actual data. Theano’s webpage provides documentation and a tutorial.
The following code includes a Theano-based implementation of matrix factorization using batch gradient descent. The parameters are similar to those in the quuxlabs matrix factorization implementation. D is a second-order masked numpy.ndarray (e.g., a ratings matrix, where the mask indicates missing ratings), and P and Q are the initial matrix factors. The elements of P and Q are the parameters of the model, which are initialized by the function’s caller. The rank of the factorization is specified by the dimensions of P and Q. For a rank-k factorization, P must be 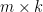
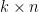
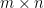
The code doesn’t contain any derived gradients. It specifies the loss function and the parameters that the loss function will be minimized with respect to. Theano figures out the rest!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import numpy as np | |
| import numpy.ma as ma | |
| import theano | |
| from theano import tensor as T | |
| floatX = theano.config.floatX | |
| def getmask(D): | |
| return ma.getmaskarray(D) if ma.isMA(D) else np.zeros(D.shape, dtype=bool) | |
| def matrix_factorization_bgd( | |
| D, P, Q, steps=5000, alpha=0.0002, beta=0.02): | |
| P = theano.shared(P.astype(floatX)) | |
| Q = theano.shared(Q.astype(floatX)) | |
| X = T.matrix() | |
| error = T.sum(T.sqr(~getmask(D) * (P.dot(Q) – X))) | |
| regularization = (beta/2.0) * (T.sum(T.sqr(P)) + T.sum(T.sqr(Q))) | |
| cost = error + regularization | |
| gp, gq = T.grad(cost=cost, wrt=[P, Q]) | |
| train = theano.function(inputs=[X], | |
| updates=[(P, P – gp * alpha), (Q, Q – gq * alpha)]) | |
| for _ in xrange(steps): | |
| train(D) | |
| return P.get_value(), Q.get_value() |
The preceding code is not completely analogous to the quuxlabs matrix factorization implementation, since their implementation uses stochastic gradient descent, and the preceding code uses batch gradient descent.
The Theano-based implementation below uses stochastic gradient descent. It retains automatically derived gradients, but in my opinion it’s less elegant than the code above.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def matrix_factorization_sgd( | |
| D, P, Q, steps=5000, alpha=0.0002, beta=0.02): | |
| P = theano.shared(P.astype(floatX)) | |
| Q = theano.shared(Q.astype(floatX)) | |
| P_i = T.vector() | |
| Q_j = T.vector() | |
| i = T.iscalar() | |
| j = T.iscalar() | |
| x = T.scalar() | |
| error = T.sqr(P_i.dot(Q_j) – x) | |
| regularization = (beta/2.0) * (P_i.dot(P_i) + Q_j.dot(Q_j)) | |
| cost = error + regularization | |
| gp, gq = T.grad(cost=cost, wrt=[P_i, Q_j]) | |
| train = theano.function(inputs=[i, j, x], | |
| givens=[(P_i, P[i, :]), (Q_j, Q[:, j])], | |
| updates=[(P, T.inc_subtensor(P[i, :], -gp * alpha)), | |
| (Q, T.inc_subtensor(Q[:, j], -gq * alpha))]) | |
| for _ in xrange(steps): | |
| for (row, col), val in np.ndenumerate(D): | |
| if not getmask(D)[row, col]: | |
| train(row, col, val) | |
| return P.get_value(), Q.get_value() | |
Lastly, the code below runs the two Theano-based matrix factorization implementations and a modified version of the quuxlabs implementation (minor modifications were made for consistency with the code above). The input data is the same ratings matrix used in the quuxlabs post and a rank-2 approximation is used for the factorizations.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def matrix_factorization_quux( | |
| D, P, Q, steps=5000, alpha=0.0002, beta=0.02): | |
| K = P.shape[1] | |
| P = np.copy(P) | |
| Q = np.copy(Q) | |
| for step in xrange(steps): | |
| for i in xrange(len(D)): | |
| for j in xrange(len(D[i])): | |
| if not getmask(D)[i, j]: | |
| eij = D[i, j] – np.dot(P[i, :], Q[:, j]) | |
| for k in xrange(K): | |
| P[i, k] = P[i, k] + alpha * (2 * eij * Q[k, j] – beta * P[i, k]) | |
| Q[k, j] = Q[k, j] + alpha * (2 * eij * P[i, k] – beta * Q[k, j]) | |
| return P, Q | |
| if __name__ == '__main__': | |
| D = np.array([[5, 3, -1, 1], | |
| [4, -1, -1, 1], | |
| [1, 1, -1, 5], | |
| [1, -1, -1, 4], | |
| [-1, 1, 5, 5]]) | |
| D = ma.masked_array(D, mask=D==-1) | |
| m, n = D.shape | |
| K = 2 | |
| P = np.random.rand(m, K) | |
| Q = np.random.rand(K, n) | |
| np.set_printoptions(formatter={'all': lambda x: str(x).rjust(2)}) | |
| print 'Ratings Matrix\n', D, '\n' | |
| np.set_printoptions(precision = 2, formatter=None) | |
| P_theano_bgd, Q_theano_bgd = matrix_factorization_bgd(D, P, Q) | |
| print 'Theano Batch Gradient Descent\n',\ | |
| np.dot(P_theano_bgd, Q_theano_bgd), '\n' | |
| P_theano_sgd, Q_theano_sgd = matrix_factorization_sgd(D, P, Q) | |
| print 'Theano Stochastic Gradient Descent\n',\ | |
| np.dot(P_theano_sgd, Q_theano_sgd), '\n' | |
| P_quux, Q_quux = matrix_factorization_quux(D, P, Q) | |
| print 'quuxlabs\n', np.dot(P_quux, Q_quux), '\n' |
Here’s the output:
Ratings Matrix [[ 5 3 -- 1] [ 4 -- -- 1] [ 1 1 -- 5] [ 1 -- -- 4] [-- 1 5 5]] Theano Batch Gradient Descent [[ 5. 2.98 2.76 1. ] [ 3.98 2.38 2.38 1. ] [ 1.07 0.85 4.75 4.99] [ 0.97 0.74 3.84 3.99] [ 1.57 1.14 4.96 5.01]] Theano Stochastic Gradient Descent [[ 4.98 2.97 2.74 1. ] [ 3.97 2.38 2.36 1. ] [ 1.06 0.85 4.77 4.98] [ 0.97 0.75 3.86 3.98] [ 1.54 1.13 4.96 4.99]] quuxlabs [[ 4.98 2.97 2.74 1. ] [ 3.97 2.38 2.36 1. ] [ 1.06 0.85 4.77 4.98] [ 0.97 0.75 3.86 3.98] [ 1.54 1.13 4.96 4.99]]
Theano Stochastic Gradient Descent and quuxlabs factorizations produce the same approximation for the ratings matrix, as they both use stochastic gradient descent to learn the model parameters. The approximation from Theano Batch Gradient Descent is slightly different, given that each iteration of batch gradient descent uses all the ratings, making it inherently different than stochastic gradient descent, which uses a single rating for each iteration.
The full Python source code of this post is available at https://